简单的说,布隆过滤器就是将多个哈希函数的计算结果映射在一块存储区域(空间)上。
布隆过滤器主要应用于一些允许计算结果有一定错误率的场景,或者说,允许二次校验的场景。最常见的应用就是:重复数据查找。
布隆过滤器工作原理:
第一步:准备好一个存储空间,将空间全部置零。空间大小一开始定值是多少就是多少,后期不能改变。
第二步:将原始数据用多个哈希函数计算出结果,有多少个哈希函数,就有多少个结果。
第三步:将计算结果映射到之前准备的空间的某一位置上(即置1)。
第四步:开始判断,如果所有映射的位置都曾经被映射过,那么就说明这个数据
有可能曾经出现过了;如果有任意一个位置从没被映射过,那么这个数据
一定是第一出现。
用图来表示吧:

上图1假设我们已经做好了第一步,准备好了空间;也准备好了三个哈希函数,分别是:f1,f2,f3;有三个数据需要判断是否第一次出现,这三个数据分别是X,Y,Z。
第二步:每当对一个数据进行查找时,就将这个数据用三个哈希函数计算,得到三个哈希值。
第三步:然后用这三个哈希值按照某个公式(最简单的是取余数)映射到空间对应的位置上(
已经被映射过的空间填写1;从未被映射过的空间填0)。
例如上图1里面,数据X和数据Y经过三个哈希函数计算最后的映射位置:
f1(x),f2(x),f3(x)最后分别映射到空间的位置是:第一位,第四位,第八位。
f1(y),f2(y),f3(y)最后分别映射到空间的位置是:第三位,第七位,第四位。
第四步:开始判断,由于一开始,所有位置都是空的,所以数据X将被判断为第一次出现;接下来到数据Y,数据Y的f3(y)函数映射到第四位,虽然这个位置被标记已使用,但是Y还有两个函数f1(y)和f2(y)映射到的位置是没有被使用过的,也就是说,满足了一下条件:
如果有任意一个位置从没被映射过,那么这个数据一定是第一出现。所以数据Y虽然有一个位置跟数据X重合,但是数据Y依然被判断为第一次出现。
这就是布隆过滤器的原理,基于这个原理,可以明显看出,布隆过滤器是存在一些问题的,比较突出的问题是:错误率。就是有可能把一个新的数据误认为是已经出现过的旧数据。例如下面的图2:
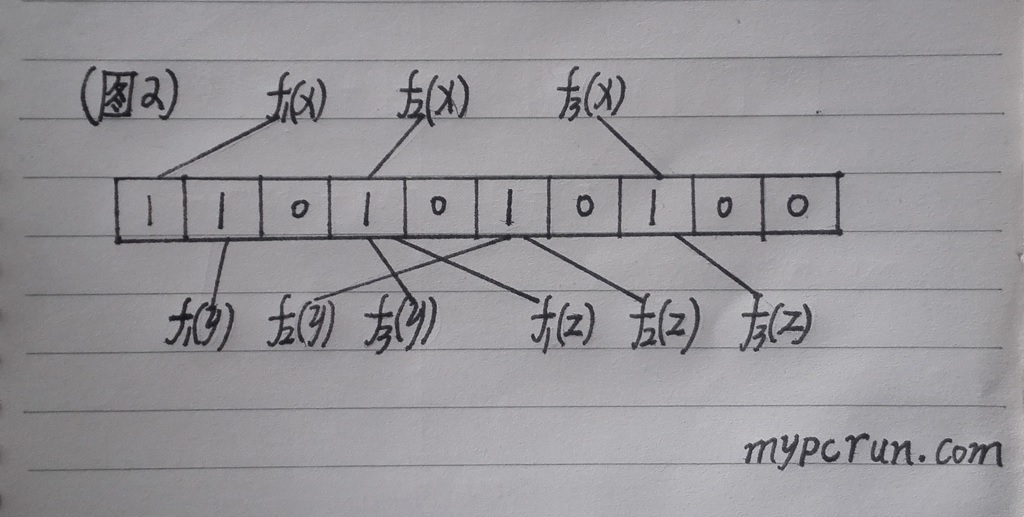
在图1的基础上,现在要对一个新数据Z进行判断,但是由于函数f1(Z),f2(Z),f3(Z)所映射的位置分别为:第四位,第六位,第八位。而这三个位置全是曾经被其他数据映射过的,所以数据Z将会被误认为是重复的旧数据。
如何避免错误?
无法避免,这个只能说是尽量降低错误率。想降低错误率,可以增大空间,也可以增加哈希函数个数,但是增加哈希函数个数,虽然会减少误判,同时也会加快的消耗空间,因为空间大小后期不能改变,当空间被消耗到一定程度,错误率将会急剧增加。所以比较好的方法是,使用适量的哈希函数个数,空间越大越好。
另外一个问题就是,由于空间大小是不能变动的,所以设计时就相当于限制了以后可以处理的数据量,当数据量达到设计值时,就不能再使用这个过滤器了。
其实这个问题是可以解决的,就是将新的布隆过滤器和旧的进行串联,查询数据的时候逐个查询。
最后还有个缺点,因为一个位置可能会被多个数据映射,所以布隆过滤器只能添加新数据,不能修改和删除。
说完了布隆过滤器的缺点,再说说它的优点,优点就是速度快,占用空间小,在计算机里,可以用1位(一个字节有8位)来表示某个位置。
额外说的一些事情:
其实,我认为在第二步的时候,不必限制在哈希函数,第二步要的是一个尽量分散的数值(越分散越好),而使用哈希函数,是因为其可以产生散列数值。我试过,用一个比较好的随机函数,也是可以代替其中一个哈希函数的,方法就是用原始数据转化为随机种子,然后再调用随机函数产生映射数值,因为当随机种子相同时,得到的随机数也是相同的,然而好的随机函数是可以产生比较分散的数值的。
总的来说,一句话概括:
布隆过滤器是一个带有错误率的快速查找器,不适合所有场景,但对于一些特殊场景,却是非常好的方案。
这个代码很老了,不记得什么时候写的了,貌似是2012年之前写了~~
调用方法:
先调用CreatebloomIndexFile创建一个布隆过滤文件,注意:这个函数会覆盖掉已经存在的旧文件,所以只有在需要创建新的布隆过滤器的时候才调用这个函数,以后使用同一个布隆过滤文件的时候,只需要调用LoadbloomIndexFile装载布隆过滤器文件。将文件装载成功后,就可以反复调用SearDataFrombloomFile函数,对数据进行过滤了。
**********************************************************************************
功能: 创建布隆索引文件
参数:
strFilePath: 文件路径
CanSaveDataCount: 希望能过滤的数据总量
返回值: 无
extern "C" __declspec(dllexport) void __stdcall CreatebloomIndexFile(const char* strFilePath,unsigned int CanSaveDataCount);
**********************************************************************************
功能: 装载已经存在的布隆索引文件
参数:
strFilePath: 文件路径
buf: 数据缓冲区
buflen: 缓冲区最大长度,如果函数执行成功,将返回缓冲区里的数据长度
needSpaceSzie: 缓冲区最少需要的长度
返回值: 装载成功返回TRUE,失败返回FALS
extern "C" __declspec(dllexport) bool __stdcall LoadbloomIndexFile(const char* strFilePath,char* buf,unsigned int* buflen,unsigned int* needSpaceSzie);
**********************************************************************************
功能: 判断数据是否在索引文件内,
此函数线程不安全,如果多线程调用此函数,需要用同步锁(互斥)机制。
参数:
DataBuf: 要判断的数据缓冲区
DataBuflen: 要判断的数据缓冲区长度
bloomFilebuf: 布隆文件的缓冲区
needSpaceSzie: 布隆文件缓冲区的长度
bolReadOnly: True: 只查询;False: 查询并写入
返回值: 如果在过滤器内返回TRUE,否则,返回FALSE
extern "C" __declspec(dllexport) bool __stdcall SearDataFrombloomFile(const char* DataBuf,unsigned int DataBuflen,char* bloomFilebuf,unsigned int bloomFilebuflen,bool bolReadOnly);
DLL下载地址:
bloomfilter.dll

 »Windows系统里,什么是临时文件?是如何产生的?
»Windows系统里,什么是临时文件?是如何产生的? 大肚鹅: [2024-07-13] : 感谢ThinkBoook14+ 2023锐龙版降级重装WIN10显示有个未知设备。找不到驱动。偶� …
大肚鹅: [2024-07-13] : 感谢ThinkBoook14+ 2023锐龙版降级重装WIN10显示有个未知设备。找不到驱动。偶� … 2020-01-24
2020-01-24 
 浏览次数:580
浏览次数:580 



