大量理论的语句就不写的了,不够直观,不利于理解,老规矩,直接举例生活中的例子,一例胜千言。
现在有6个苹果,已经被分好等级了,有三个类别,分别为:甜,不甜,很甜。下面就是每个苹果的数据了:
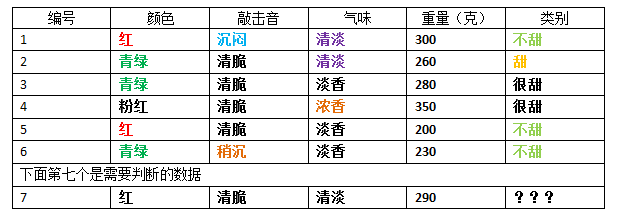
现在有一个新的苹果(编号7),得知这个新苹果的数据为:(红色,清脆,清淡,290克),根据上面的表格数据来判断,这个新的苹果属于哪个类别呢?甜?不甜?很甜?

从上面的图一可以看到,这就是决策树,树的每一个节点就是一个决策,每一个叶子节点就是一个结论,把需要判断的新数据,根据节点上的流程走,就可以得到答案了。
或许有人会有疑问,图一是唯一结构吗?不按照这个可以吗?当然可以,图二就是了。
“哦,原来这就是决策树,乱来一通也行,只要是个树结构就行,懂了,再见~~”
“道友请留步!你没听我说完,我是说过这个结构可以,但得到的判断结果,会有很大的误差。”
那么如何得到一个判断结果比较准确的决策树呢?
其实从结构可以看出,
建立一科好的决策树,就是要找一个比较好的属性值作为分割点,使其分成的左右两边的数据集里的类别,尽量的纯(纯度越高越好)。以至于能达到一种效果:左边的数据里,全是或者几乎是同一类;右边的数据里,全是或者几乎是同一类。如下图所示:

上图里显示的,当以某属性里的某个值作为分割点,左边的数据集,“甜”占了很大一部分;右边的数据集里,“不甜”占了很大一部分,这样的划分才是合理的。
如何理解这样的划分用意?可以这么理解:当某个新事物的某属性,属性值为X时,那么就进入左子树,由于左子树里的数据绝大部分都是“甜”,那么新事物被判断为甜,出错率很小;当属性值不是X时,就进入右子树,由于右子树大部分数据都是“不甜”,所以新事物就被判断为不甜,出错率也在可接受范围内。理论上,左边最好全都是“甜”,右边最好全都是“不甜”,这样判断就100%正确,然而现实中很难能遇到这种情况。
现在问题来了,在某个节点里,如何选属性?属性选好后,如何选此属性下的哪个值作为分割点?
这个问题,无法得到直接答案,需要对每一个属性值都计算,才知道答案(嗯,是的,就是这么简单粗暴~)。
从“
颜色”属性开始,这个属性有三个选项值,分别是:红,青绿,粉红。
当颜色取
红色作为分割值的时候,得到左右两个数据集:
左数据集:都是颜色值为红色的数据,数据一共有2条(第1条和第5条记录),这个数据里面的类别都是“
甜”,这个分类在左数据集里,所占的比例:
P(甜|左数据集)=2/2,那么左数据集的计算值为零:

哦对了,忘记说了,计算一个集合的纯度的公式是(也称为某个集合的基尼系数,但实际上我不是很喜欢这个称呼,
实际上就是计算每一个类在数据集合里的比例值。),值越小,代表这个集合的纯度越高,纯度越高,说明集合里的某一个分类占的比例越多:

N是某个类别,M是类别数量
右数据集:都是颜色值为非红色的数据,非红色数据一共有4条(第2,3,4,6记录),这个数据里的类别分别有“甜”,“很甜”,“不甜”三个,这三个分类在右数据集里,所占的比例:
P(甜|右数据集)=1/4
P(很甜|右数据集)=2/4
P(不甜|右数据集)=1/4那么右数据集的的基尼指数为五分之八(5/8):

通过上面的公式计算出,如果颜色取值为红色的话,总体基尼指数为:

D(left)=左边的数据量
D(right)=右边的数据量
D=D(left)+D(right),其实就是总的数据量
D(left) / D和D(right) / D的用意是,将它们所占的数据比例数作为权重
最终总的基尼指数就是:Gini(颜色|红色)=2/6 * 0 + 4/6 * 5/8=0.417
就这样,继续计算当颜色取其他值时:
Gini(颜色|青绿)=0.556
Gini(颜色|粉红)=0.467
继续计算其他属性,取每个值的情况:
Gini(敲击声|沉闷)=0.533
Gini(敲击声|清脆)=0.417
Gini(敲击声|稍沉)=0.533
Gini(气味|清淡)=0.500
Gini(气味|浓香)=0.467
Gini(气味|淡香)=0.556
Gini(重量|?),哦等等,貌似遇到了问题,重量可是连续值,不是离散值(实际上我也不喜欢这么个称呼,
我认为将离散值称为枚举值,还更贴切),怎么办?
很简单,跟排序二叉树一样,把小于等于某个值的数据放左边,剩余的放右边。从第一天记录开始,值是300,那么左边的数据集全是小于等于300,右边的数据全是大于300
所以左边的数据集是[1,2,3,5,6],右边的数据集是:[4]。
左边数据集有3个类别:“不甜”,“甜”,“很甜”,类的分布概率为:
P(小于等于300|左边)=1 – (3/5)*(3/5) – (1/5)*(1/5) – (1/5)*(1/5)=14/25
右边数据集有1个类别:“很甜”,类的分布概率为:
P(大于300|左边)=1 – (1/1)*(1/1)=0
基尼指数为:
Gini(重量|300)=(5/6) * (14/25) + (1/6) * 0=0.467
同理,继续将剩余的每一条数据都计算一次
Gini(重量|260)=0.444
Gini(重量|280)=0.583
Gini(重量|200)=0.533
Gini(重量|230)=0.417
Gini(重量|350),这个不用算,因为这个值是最高的,如果还分的话,右子集的数据都是空的了,
如果用某一个值划分,当分出的右数据集是空的时候,那么这个值就不要划分了,放弃计算。注意:
连续值属性和枚举值属性,在划分过程中有点不一样的是,连续值属性可以在其子节点中继续使用。好了,所有的基尼系数都被计算出来了,选
最小的一个,作为分割点,最小的基尼系数是:
Gini(颜色|红色)=0.417
Gini(敲击声|清脆)=0.417
Gini(重量|230)=0.417
一共有三个,所以随便选一个作为当前节点,这里选的是“颜色”属性,得到的树结构就是:

对于左右两个数据集,是否还有继续分下去?这个没有标准答案,由现实的应用场景来决定,停止继续建立新节点的条件一般都有以下几种情况:
1 数据集的基尼指数达到设定值,通俗的说,就是里面的类的纯度达到一定值。
2 数据集为空。
好了,采用以上方法,建立好决策树之后,就可以将新数据根据属性逐个判断了。
对于叶子节点,其数据集里,哪种类型占的比例多,就被判断为哪种类型。
另外,在建立数据集的时候,要注意的是:
对于已经使用过的属性(离散值类型),在其所有子节点,都不能再使用,但是连续值类型的属性例外!决策树虽然完全建立了,但是整个过程还没完整,还需要对这棵树进行修剪,俗称剪枝。为什么要这么做?就是防止过拟合。把训练集数据的特征都当做所有未知数据的特征,这就是过拟合,不利于泛化。
决策树的剪枝: 剪枝的核心思想就是:
防止过拟合,预防将训练集数据的特殊个性当成普遍共性。方法有好多种,其中两种比较常用:
1 找一批已经分类正确的数据当做验证集,从最后一层节点开始,假设剪掉某个节点前后,用验证集数据去计算,剪掉前的准确率(对叶子进行计算)和剪掉后的准确率(对单节点进行计算),如果剪掉后的准确率没有下降,那么就减掉所有子节点,将当前父节点变成叶子。
2 采用损失评估。
子树的损失函数:Ca(T)=C(T)+a|T|
C(T)是训练数据的预测误差,错误率,也可以用基尼指数来替代。
a是权衡训练数据的拟合度与模型的复杂度。
|T|是以T为根节点的所有叶子数量。
剪掉叶子后的节点,记录为小写字母t,因为叶子没有了,所以这个时候的损失函数变成:Ca(t)=C(t)+a
随着a的减小,甚至a=0时,Ca(T) < Ca(t)是必然的,为啥?因为建立树的原则就是:
当前节点的数据集纯度还达不到设置值,还要继续分下去,所以对于每一个父节点,父节点的数据分类纯度肯定比它的子节点凌乱。
随着a 的增大,Ca(T)也逐渐增大,总会出现某一个a值,使得Ca(T)=Ca(t),这个时候,意味着一个事实:
当前节点剪掉之后(即丢掉它的所有子节点)的错误率和不剪枝一样,那么为了实现泛化,去掉过多的个性数据,所以肯定选择剪枝了。
这个时候:Ca(T)=Ca(t),就是C(T)+a|T|=C(t)+a,得到:a=(C(t)-C(T)) / (|T|-1)
接下来就容易了,对整颗完整的树进行计算,选取最小a值的一个节点,然后将这个节点剪掉,然后得到一个树Ti,将这棵树用新的验证集去验证,将得到的准确率值Pi记录下来,保存到一个数组。接下来,再继续对Ti这棵树进行上面重复的动作,记录每一个准确率值。
由于每一个Pi值对应一个Ti值,所以,选出准确率最大的值,这就是最终需要的决策树。
其实上面使用的方法就是CART方法,产生的决策树是一个二叉树,用ID3和C4.5将会产生多叉树(当前节点对应的属性,其属性值有多少种(连续值除外),就有多少个分支,一个属性值就是一个分支),这两种算法选取最优属性的方法是采用信息增益的方法来选,
但是我认为也可以采用基尼指数来替代信息增益,具体做法就是:计算每一个分支下的集合的概率分布值,然后累加总和,得到的总值就是基尼指数,选取最小值作为最优属性。例如:当进行到某个节点是,有A,B,C三个属性,那么就有三个分支,计算这三个分支的数据集的概率分布,获取基尼指数,此方法后期打算做实验观察实际效果。
建立决策树的总结归纳:
1 利用某个公式(基尼系数或信息增益)在所有属性里找出某个属性值,以此属性值作为划分点,能使其下每个子节点的数据集里的某个类占的比例尽量多,逐层建立树节点。
2 将建立好的决策树进行剪枝,如果剪掉某个节点后,准确率没有下降,那么就剪掉此节点。
最后要说明的是,我认为数据集是有使用环境限制的,也就是说从A地方采集到的数据,训练好的决策树,最合适A地方,但不一定合适B地方。举个例子:南方城市的消费饮食习惯数据局,不一定适用北边城市。山地上种出的西瓜,和沙地上种出的西瓜,判断好坏的标准不一样。企图用一个局部数据进行全局通用,是行不通的,这个与算法无关,算法再牛,也解决不了盲目的不切实际的问题。

 »Centos 挂载新硬盘,格式化,并映射到其他文件夹
»Centos 挂载新硬盘,格式化,并映射到其他文件夹 »Centos 6.X 无法安装gcc,也不能使用yum解决办法
»Centos 6.X 无法安装gcc,也不能使用yum解决办法 游客: [2024-05-09] : 你好,联想笔记本电脑插入U盘蓝屏,下载文件后插入U盘还是没有解决,请� …
游客: [2024-05-09] : 你好,联想笔记本电脑插入U盘蓝屏,下载文件后插入U盘还是没有解决,请� … 2020-03-21
2020-03-21 
 浏览次数:1948
浏览次数:1948 


